If you know anything about me, is probably that I make Clippy as fast as I can. I love making programs faster both because (a) it’s a puzzle, because (b) I don’t think that we should expect users to have access to high-end hardware in order to compile a program and because (c) the energy footprint is smaller, which satisfies my ideological fight against waste.
So some time after I joined the Clippy, I started dabbling into performance squeezing for our famously slow linter. As Clippy injects itself into the compiler, and we obligatory have to compile your program in order to analyze it, we are limited by the compiler itself. But that doesn’t mean that everything is lost!
From lint filtering (running only lints mentioned in your source code) to optimizing routines that their implementors thought wouldn’t need to be optimized because of their sparse use. Everything counts and I have the necessary numbers to prove that.
To the numbers! Exploding transition
The numbers in question
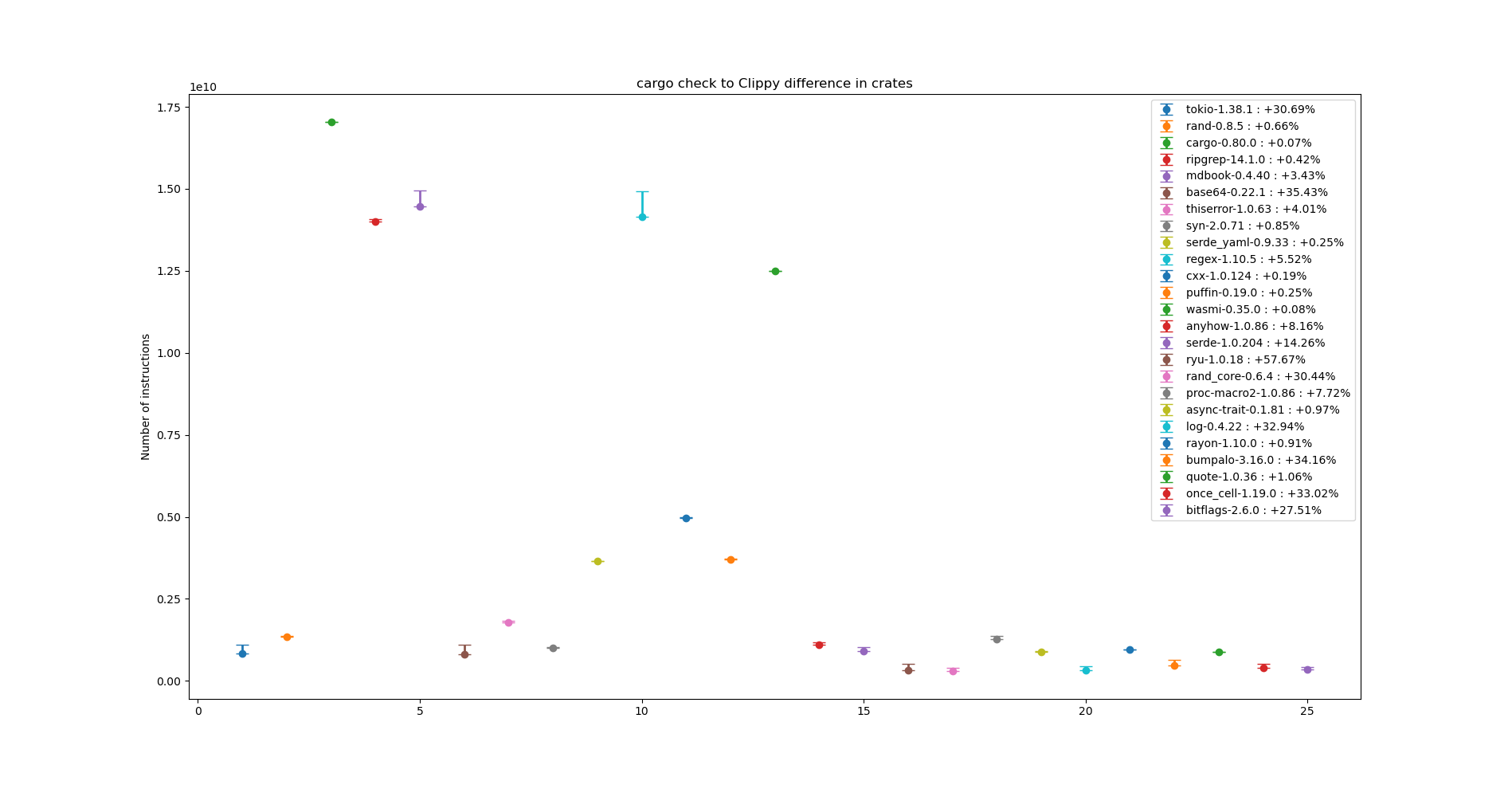
As you can see, the numbers differ a lot depending on how a given project may be structured. Some deciding factors are:
- Is the project a binary or a library?
- How many dependencies does your project have.
- How many documentation lines does your project have?
- Does your project configure a MSRV?
- How complex is your trait use? Does your project use a lot of complex trait obligations?
- What lints does your project enable with
#[warn]and what#![allow]s are present.
Some ratios present in the graph are Cargo itself, with just a +0.08% runtime difference.
On libraries there’s a lot of difference though. For example, quote only presents us with a +1.06%
runtime difference, but tokio has a +30%.
While benchmarking tools for Clippy were not present when I started working on
Clippy performance, I manually benchmarked tokio comparing 1.81.0 (when I
started the official project goal, not when I started the optimization efforts)
to today’s Clippy. It yielded a 38.042% decrease in runtime, that’s equivalent
to 843 million instructions saved! And what’s better, this benchmark was before
jemalloc was implemented into Clippy by Kobzol!
So today’s numbers are even better (in some cases 7-9% better)!
What’s next
Next in line is making parallel linting possible. Currently Rust’s linting system is not parallel and that can be a great impediment when taking performance to the next level. I also have some ideas to implement in the incremental compilation department, which is a field of research I’ve ignored for a long time mainly because it’s difficult.
(Just go ask the rust-analyzer team for their Salsa project, and I’m sure they have war stories engraved in their minds)
Conclusion
This long period of devoting myself to making Clippy better has been great. I’m happy mantaining this project and hearing users talk about how Clippy is the best linter they’ve used. My mind is corrupt with all the bugfixes I review every day so sometimes I forget that Clippy produces generally good advice.
Thanks for sticking with me in this journey, and see you all in the next irregular performance status update!
Peace! ✌