rustdoc is the tool used in the Rust ecosystem to generate
documentation from the code. Generating documentation from code isn’t a new concept, but I find that rustdoc’s
implementation is the best one yet.
In this blog post, we’ll analyze other tools like it for other languages (Sphinx for Python, Doxygen for C++ and other, JSDoc for JavaScript and Godoc for Go) seeing examples from real-world projects in each one of them. Then, we’ll recapitulate over the learned, and we’ll compare it to rustdoc.
As an aside-note, we’ll also talk about integration in the code. How easy it’s to write the documentation with the different tools and how cluttering does it look in the end.
Sphinx
Sphinx is not only a “per-class” documentation generator, but it also has support for independent pages (similar to
mdbook), in an all-in-one package. Note that these independent pages are in
the .rst (reStructuredText) format, instead of the “standard”
Markdown (although this can be changed with some configuration).
It supports the use of themes, bits of HTML and CSS used to personalize your documentation. This is a great plus
that we don’t really have with rustdoc. We have the hacky solution of adding HTML headers:
[package.metadata.docs.rs]
rustdoc-args = [ "--html-in-header", "<HTML HEADER>" ]
Other than that hacky solution, rustdoc only has
some basic pre-defined settings.
A great example of Sphinx doing its best would be NumPy’s user guide. It contains a simple layout but it works. A table of contents at the left, below the search bar, and the main content on the right, covering ~70% of the screen.
But this is all functionalities that would cover mdbook! (and that it covers). We can try searching something
on the search bar to see the results of something more similar to what rustdoc tries to do.
For example, by searching for ctypeslib in NumPy’s docs and clicking the first result, it will take us to
this page. It contains all
functions that contain the string ctypeslib. In a list-like scheme, something like:
lib.module.function_name(arg1, arg2)[source]- Documentation…
Note that extra tab when presenting the documentation + making the function signature bold was a good design decision to create contrast. Even then, it doesn’t do much more for grouping concepts (a function doesn’t differentiate much from a class).
Also, the mid-search screen is pretty bad. It doesn’t visually distinguish object type (You cannot easily tell what kind of object you’re looking at, you’d need to read the “Python module / function / …”)
Note: I chose Sphinx because it’s one of the most well-known documentation generators for Python, but there are a lot more.
In the regards of visual clutter in the code, Python does it pretty good. Documenting a function isn’t hard nor tedious (which leads to better documented code). An example of such a function:
def sum_one(a: int) -> int:
"""A function that sums one to a number 'a'"""
return a + 1
Doxygen
Doxygen started back in 1997. And as we can see in its pages (e.g. CGAL documentation), it hasn’t changed much since those times.
We have a sidebar at the left, with collapsible (collapsed by default) nested sections. Doxygen has independent pages as well as normal code documentation.
Searching in a module (example) because there are no visual aids, like coloring classes and structs different colors. Instead, we have to read the text alongside the object’s name (a non-shortened name, like CGAL::Concurrent_compact_container_traits< T >)
On the topic of a page, we can analyze
CGAL::Fourtuple<T>.
We can see that code doc pages are pretty well done. They contain a “Definition” header, containing a general
description of what the user does + structured information (and other minor info). In the case of CFGAL::Fourtuple<T>, associated types,
variables and creation.
Doxygen’s code doc pages are pretty useful information-wise, even with their outdated looks. But… Here’s the main problem.
The main problem
Ok, the output looks good, how does the input look? Well… Not good. Here’s the input code of the page I talked about earlier:
/*!
\ingroup PkgSTLExtensionUtilities
The `Fourtuple` class stores a homogeneous (same type)
fourtuple of objects of type `T`. A `Fourtuple` is much like a
container, in that it "owns" its elements. It is not actually a model of
container, though, because it does not support the standard methods (such as
iterators) for accessing the elements of a container.
\deprecated This class is deprecated, and will be removed in some future \cgal release.
Please use std::array instead.
\tparam T must be `Assignable`.
*/
template< typename T >
class Fourtuple {
public:
/// \name Types
/// @{
/*!
*/
typedef T value_type;
/// @}
/// \name Variables
/// @{
/*!
first element
*/
T e0;
/// @}
/// \name Variables
/// @{
/*!
second element
*/
T e1;
/// @}
/// \name Variables
/// @{
/*!
third element
*/
T e2;
/// @}
/// \name Variables
/// @{
/*!
fourth element
*/
T e3;
/// @}
/// \name Creation
/// @{
/*!
introduces a `Fourtuple` using the default
constructor of the elements.
*/
Fourtuple();
/// @}
/// \name Creation
/// @{
/*!
constructs a `Fourtuple` such
that `e0` is constructed from `x`, `e1` from `y`,
`e2` from `z` and `e3` from `t`.
*/
Fourtuple(T x, T y, T z, T t);
/// @}
}; /* end Fourtuple */
… I know, it’s lengthy.
Doxygen uses heavy post-processing for understanding your doc comments. With a $\LaTeX$-like syntax. This makes so that writing these comments and reading the code is hard and takes time.
/***************************************************************************//**
* A brief history of Doxygen-style banner comments.
*
* This is a Doxygen-style C-style "banner" comment. It starts with a "normal"
* comment and is then converted to a "special" comment block near the end of
* the first line. It is written this way to be more "visible" to developers
* who are reading the source code.
* This style of commenting behaves poorly with clang-format.
*
* @param theory Even if there is only one possible unified theory. it is just a
* set of rules and equations.
******************************************************************************/
void doxygenBanner( int theory );
Something very cool about Doxygen is that, due to it having a language-independent design, it’s implemented not only on C++, but also C, Objective-C, C#, PHP, Java, Python, IDL (Corba, Microsoft and UNO/OpenOffice flavors), Fortran and to some extent, D.
This language neutrality really shines for multi-language projects. Where we don’t need to learn / use several documentation generation tools.
JSDoc
JSDoc is the documentation generator used in JavaScript Projects. It supports tutorials, as well as adding a README and using, to some extent, templates (mainly accessing package.json files attached to read things like version)
It has a plugin system as well as templates / themes! A very cool addition (also, they look pretty cool). The default template doesn’t look very good, it’s very simple and kinda hard to read.
JSDoc also has special syntax, like Doxygen, but with (what I consider to be) clearer tag names and the usage of @ instead of \. (e.g. @example).
On the topic of writing the documentation, I find that this doesn’t clutter a lot like Doxygen, but also doesn’t integrate perfectly like Sphinx.
/**
* Calculate tax
* @param {number} amount - Total amount
* @param {number} tax - Tax percentage
* @returns {string} - Total with a dollar sign
*/
const calculateTax = (amount, tax) => {
return `$${amount + tax * amount}`;
};
Overall, a very good documentation generator.
Godoc
Godoc is the program used to extract and generate documentation from Go programs.
It’s very simple but also simple to use. It works with normal // comments, without any tags. Furthermore, it supports examples as external functions (by calling a function ExampleMyStructure containing the example), that’s neat, I guess.
It follows Go’s simplicity and elegance.
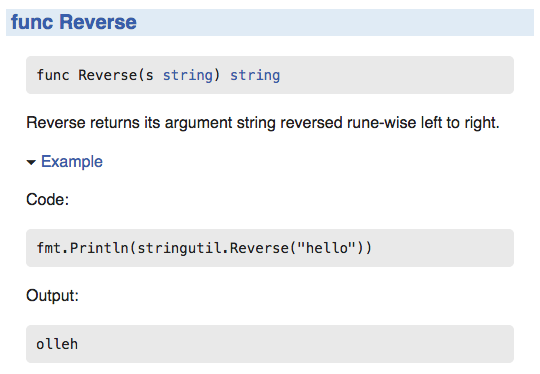
// Reverse returns its argument string reverse rune-wise left to right.
func Reverse(s string) string {
// [...]
}
func ExampleReverse() {
fmt.Println(Reverse("hello"))
// Output: olleh
}
Let’s analyze rustdoc’s design
As docs.rs uses rustdoc to generate its pages, and it’s the most widespread use of rustdoc online, we’ll use some arbitrary docs.rs pages to talk about rustdoc’s design.
rustdoc is mainly accessed locally by using cargo doc, so it’s installed along with Cargo and Rust by default using rustup. That breaks all inconveniences that installing Sphinx, Doxygen, JSDoc or Godoc could have.
But, how’s the output?
rustdoc’s output is a simple HTML web-page, it uses #[doc] attributes (usually sugared using ///) to create the code’s documentation. It doesn’t have tutorials / independent pages, as that is what mdBook specializes in.
The output can contain a general, detached documentation, usually serving as an introduction / README (example), this description is the first thing that you see when opening some rustdoc generated documentation. Now, here’s the big difference when finding items:
rustdoc focuses on searching for the items, it has a big and “centered” search bar at the top, indicating that, before searching on the big list of items down below, you should search for what you’re looking for.
When you search something, the search results update on almost every keystroke and the results will have some text coloring to visual aid. For example, functions are yellow, but macros are green, this, even though it’s a very small aid, actually helps a lot.
The algorithm used by the search bar is a fuzzy matching algorithm (also known as Approximate string matching), so it’s tolerant to typos.
This means that, when searching for something, the information is laid before your eyes in a very simple manner, letting you find for what you’re searching. (example)
When entering a page, e.g. for a function (example), it starts with the function signature (similar to Sphinx). And then continues with the documentation provided in the source code. You can click any highlighted words, and they’ll link you to their respective doc pages. This is very handy when you’re not all that familiar with an API and need to now every type that the API provides. As rustdoc uses Markdown as the language that the in-code documentation is written, it is very powerful.
The fact that rustdoc extracts the documentation from #[doc] attributes in the source code, means that we can use conditional compilation for showing different things depending on compile-time variants. Providing relevant documentation depending on things like OS. Also, external crates (Rust’s libraries) like aquamarine can use the extraction of #[doc] attributes to show things like Mermaid diagrams.
All these things together make pages generated by rustdoc (like every page in docs.rs) a breeze to navigate.
If you’re worried about how does the code look like, it doesn’t look bad. It seems like normal comments with contents written in Markdown.
/// Parse tokens of source code into the chosen syntax tree node.
///
/// This is preferred over parsing a string because tokens are able to preserve
/// information about where in the user's code they were originally written (the
/// "span" of the token), possibly allowing the compiler to produce better error
/// messages.
///
/// This function parses a `proc_macro::TokenStream` which is the type used for
/// interop with the compiler in a procedural macro. To parse a
/// `proc_macro2::TokenStream`, use [`syn::parse2`] instead.
///
/// [`syn::parse2`]: parse2
///
/// # Examples
///
/// ```
/// # extern crate proc_macro;
/// #
/// use proc_macro::TokenStream;
/// use quote::quote;
/// use syn::DeriveInput;
///
/// # const IGNORE_TOKENS: &str = stringify! {
/// #[proc_macro_derive(MyMacro)]
/// # };
/// pub fn my_macro(input: TokenStream) -> TokenStream {
/// // Parse the tokens into a syntax tree
/// let ast: DeriveInput = syn::parse(input).unwrap();
///
/// // Build the output, possibly using quasi-quotation
/// let expanded = quote! {
/// /* ... */
/// };
///
/// // Convert into a token stream and return it
/// expanded.into()
/// }
/// ```
// The following is magic to produce things like deprecation warnings, or feature gates vvvvvvv.
#[cfg(all(
not(all(target_arch = "wasm32", any(target_os = "unknown", target_os = "wasi"))),
feature = "parsing",
feature = "proc-macro"
))]
#[cfg_attr(doc_cfg, doc(cfg(all(feature = "parsing", feature = "proc-macro"))))]
pub fn parse<T: parse::Parse>(tokens: proc_macro::TokenStream) -> Result<T> {
parse::Parser::parse(T::parse, tokens)
}
And that’s how rustdoc achieves its genius design.